


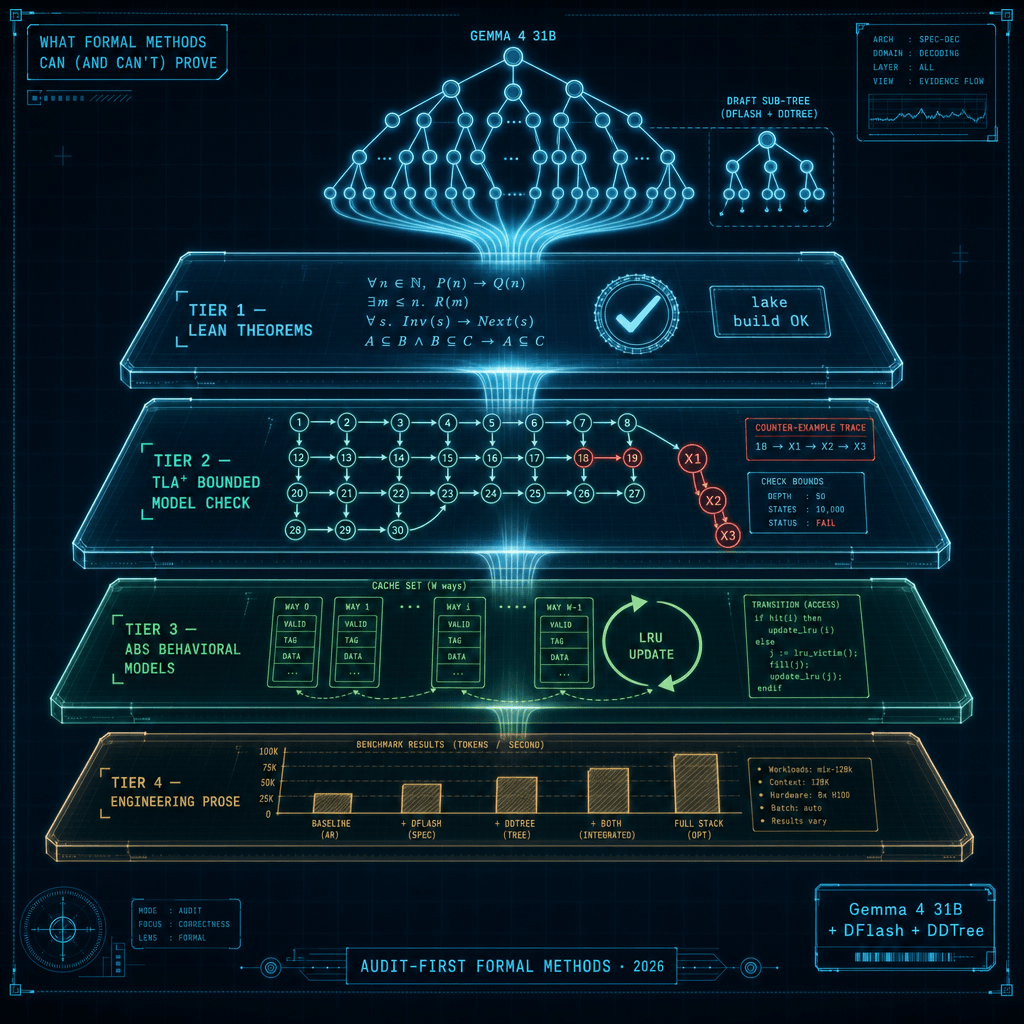
Summary
The G4-FlashTree stack — Gemma 4 31B as the target, a DFlash block drafter, and a DDTree tree verifier — is the kind of system where formal methods earn their keep, because the failure modes (ghost reads after rollback, cross-path leakage in tree masks, drafter influence on the accepted output) are concurrent and adversarial rather than statistical. We tried to formalize it. Then we audited the formalization before publishing. The audit found that several of the original artifacts were non-compiling, unparseable, or mathematically vacuous. After remediation, what survives is a four-tier evidence pyramid: four mechanically rechecked Lean theorems over ℝ, four TLA+ properties confirmed under bounded TLC (one of them load-bearing because we also captured the unsafe counter-example), three behavioral ABS models that no toolchain ran, and engineering claims that belong in powermetrics and benchmarks rather than in Lean.
Here is what this post will walk through, in order:
- The strongest single result — a TLA+ safe-vs-unsafe rollback pair where removing one guard turns a 31-state green run into a 4-state counter-example. This is the lead because pair-of-runs evidence is structurally stronger than a single green run.
- Tier 1 — Lean — four theorems,
lake buildexit 0, zerosorry. RoPE rotation, quantizer distortion bound, sliding-window softmax zero-leakage, and tree-mask ↔ path-attention equivalence (the last one closes the audit's biggest overstatement). - Tier 2 — TLA+ — four bounded-TLC properties at small state counts, with the original parse-failure logs kept as evidence of the pre-remediation state.
- Tier 3 — ABS — three behavioral models compiled and run through the
abscErlang backend; assertions pass on the captured scenarios. Logs committed alongside the source. - Tier 4 — engineering — what's not in the formal bundle and where its evidence does live.
- The "can't prove" half — nine deferred findings spanning floats vs.
ℝ, generic interfaces vs. Gemma-specific kernels, bounded model-checking vs. proof, and probabilistic non-interference as future work. - What we did differently this time — the audit-before-publish discipline.
- Recap, reproducibility, and links to every artifact.
1. The Architecture in One Paragraph
TL;DR: Speculative decoding for LLMs: a small, fast drafter proposes tokens, a big, slow verifier accepts or rejects them. G4-FlashTree adds a tree of branching proposals on top, plus Apple Silicon-specific cache and engine choices. We're going to formalize the three places this kind of system silently breaks.
Gemma 4 31B is the target distribution. DFlash drafts blocks of tokens at a much lower compute budget — typically W4 + FP16 KV, with an optional W4 + TQ 3.5-bit KV mode (weight quantization and KV-cache quantization are independent axes — W4 + FP16 KV is not the same configuration as W4 + TQ 3.5-bit KV). DDTree organizes proposed continuations into a budget-bounded tree, dispatches the verifier across the tree under a non-causal mask, accepts the longest agreeing prefix, and rolls back the rest. On Apple Silicon (M3 Ultra) the drafter weights and an FP4-to-FP16 LUT live in the 96 MB System-Level Cache, and intermediate tensors move between GPU and ANE through IOSurface-backed buffers. Three failure modes — concurrent rollback, tree-mask leakage, and drafter-induced bias — are the kind of thing speculative-decoding implementations get wrong, and the shape of properties Lean and TLA+ are good at.
2. The Strongest Single Result: A Load-Bearing Safety Guard
TL;DR: We wrote the same TLA+ spec twice — once with a safety guard, once without. The guarded version passed; the unguarded version produced a concrete 4-state failure trace in under a second. That counter-example is the actual evidence the guard matters; a single green run alone wouldn't be.
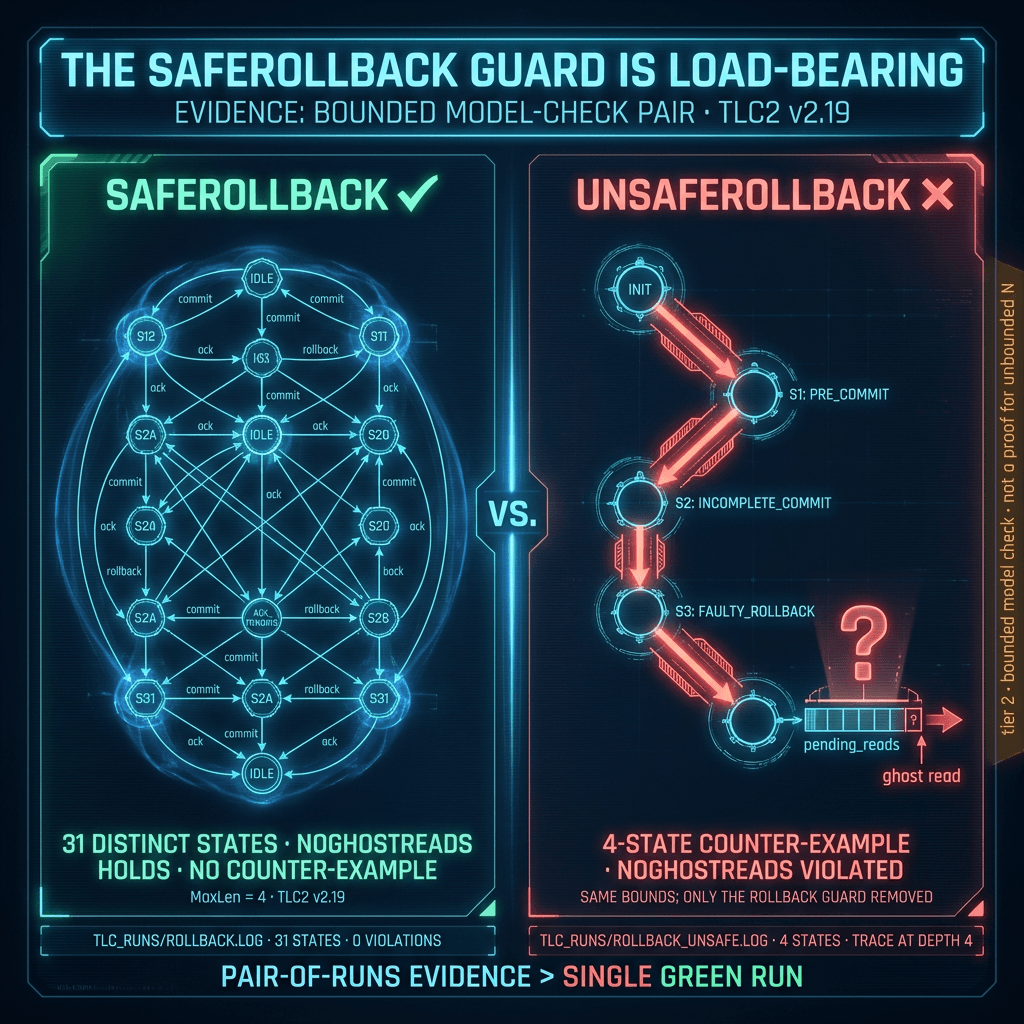
Before we walk the tiers, the most useful piece of evidence in the bundle. The TLA+ spec rollback.tla models the verifier's KV cache as an integer length len with a set pending_reads of in-flight attention reads. The intended invariant is NoGhostReads == \A i \in pending_reads : i <= len — nobody is reading past the tail. The interesting action is rollback after a rejected proposal, and it is guarded: SafeRollback requires \A i \in pending_reads : i <= k, i.e. you cannot truncate below an active reader.
We ran TLC2 v2.19 twice against the same spec, with two different Spec predicates:
- Safe spec (uses
SafeRollback): 31 distinct states atMaxLen = 4, no counter-example. →tlc_runs/rollback.log - Unsafe spec (drops the guard, uses
UnsafeRollback): a 4-state counter-example in well under a second. The trace isInit → Extend → StartRead → UnsafeRollback, terminating inlen = 0, pending_reads = {1}. →tlc_runs/rollback_unsafe.log
The pair is the evidence. The green safe-spec run alone is a 31-state finite check and would be borderline vanity. The counter-example shows exactly which conjunct of the guard is load-bearing, with a concrete, minimal trace anyone can read. TLC's job here isn't to certify safety at unbounded N; it's to keep an engineer honest about why each clause of SafeRollback is in the spec — the kind of question hand proofs tend to elide.
👉 View source: rollback.tla · rollback.cfg · rollback_unsafe.cfg
3. Tier 1 — What Lean Can Prove (Mechanically Rechecked)
TL;DR: Four math theorems run through Lean's proof checker — think of it as a compiler that won't accept your reasoning unless every step type-checks.
lake buildexit 0 means a machine has verified the chain end-to-end. Zerosorrymeans we didn't punt on any step.
Toolchain: Lean 4.30.0-rc2 + Mathlib v4.30.0-rc2, pinned in lean-toolchain and lakefile.toml. The build evidence is lake_build.log: Build completed successfully (1980 jobs), exit 0, zero sorry, zero admit, zero project-introduced axiom in surviving files.
Four theorems survived. Each proves what it states; none claims more.
A. RopeId.lean — Pythagorean rotation preserves the dot product
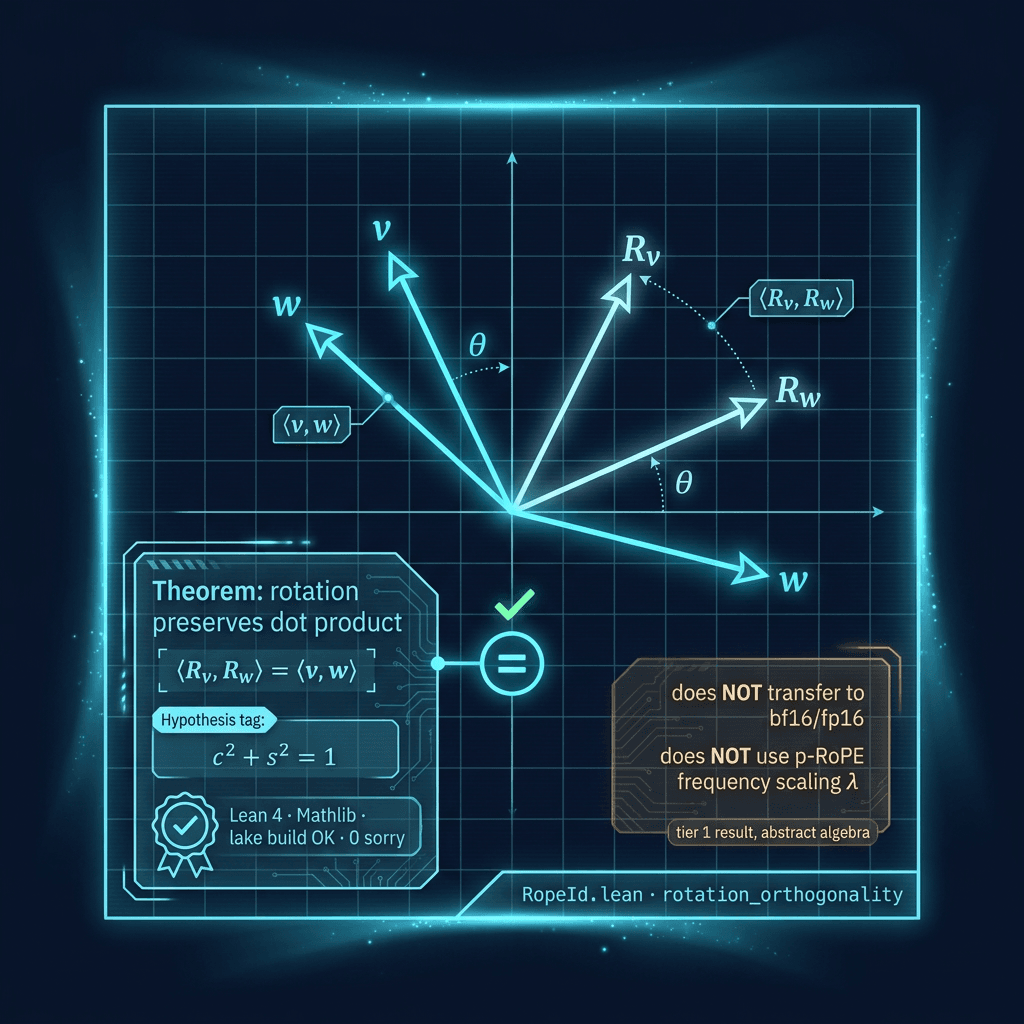
Over any commutative ring R, the standard 2D rotation (c, s) with c² + s² = 1 preserves the dot product v.x·w.x + v.y·w.y. The original ended in sorry; the remediated proof discharges via Mathlib's linear_combination. We dropped the "p-RoPE" framing in remediation: the proportional-frequency-scaling λ plays no role; this is the textbook 2D-rotation lemma.
👉 View source: RopeId.lean
B. TQTopo.lean — Quantizer inner-product distortion bound

For any real inner-product space V and any T : V → V with ‖T z − z‖ ≤ η ‖z‖, the inner product is preserved up to 2η ‖x‖ ‖y‖ + η² ‖x‖ ‖y‖ (triangle inequality plus three Cauchy–Schwarz applications). The original didn't compile (bespoke IsOrderedRing missing Sub); the remediated proof uses Mathlib's InnerProductSpace. The theorem is generic — it does not model TurboQuant's Hadamard rotation, per-block scale, or O(d^{-1/2}) distortion.
👉 View source: TQTopo.lean
C. AttnIso.lean — Sliding-window softmax-attention is zero-leakage
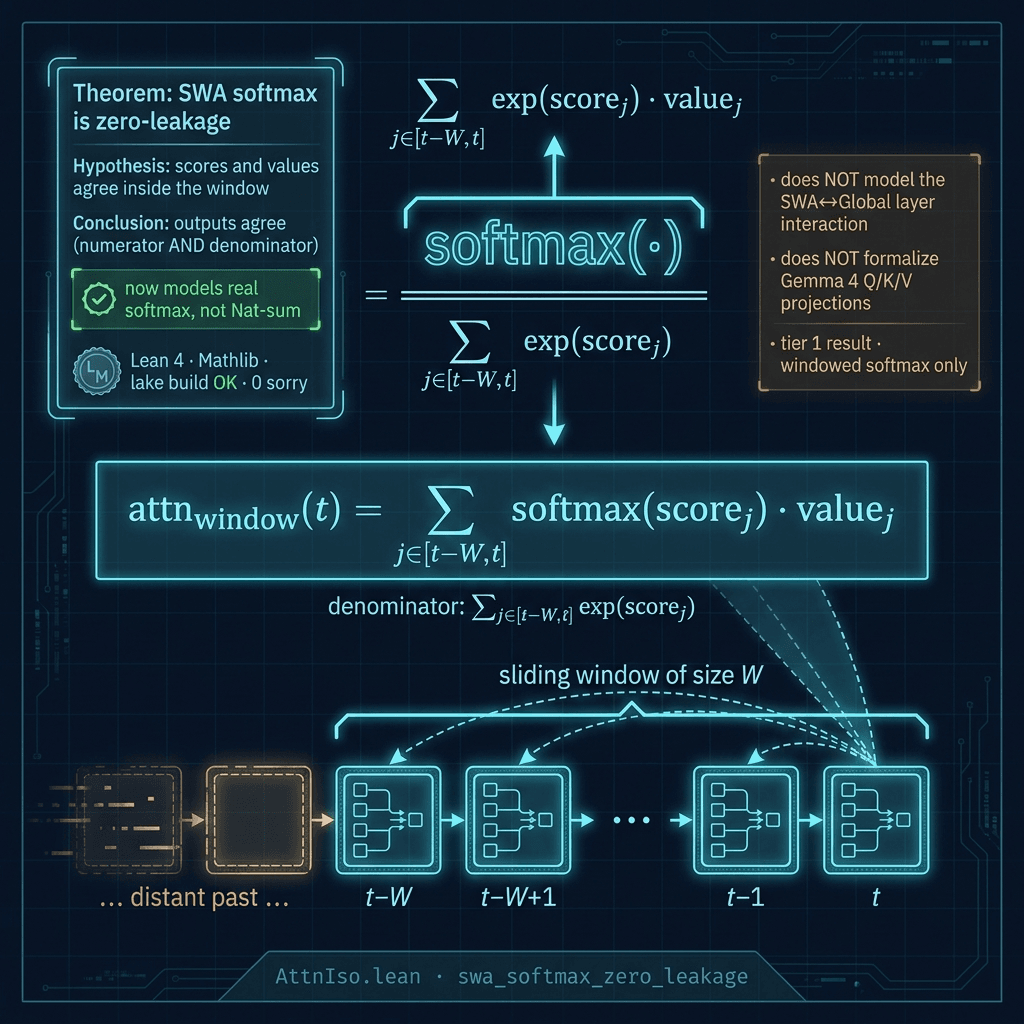
If two (score, value) pairs agree at every position the SWA mask admits, the softmax outputs at that query position are equal as elements of ℝ, including the normalizer. The original used Lean 3's lambda syntax and didn't parse; the remediated version uses fun and moves the model from Nat sums to ℝ softmax (the audit caught the original modelled "attention" as List.foldl (· + ·) 0).
👉 View source: AttnIso.lean
D. MaskEquiv.lean — Tree-mask softmax equals path-attention
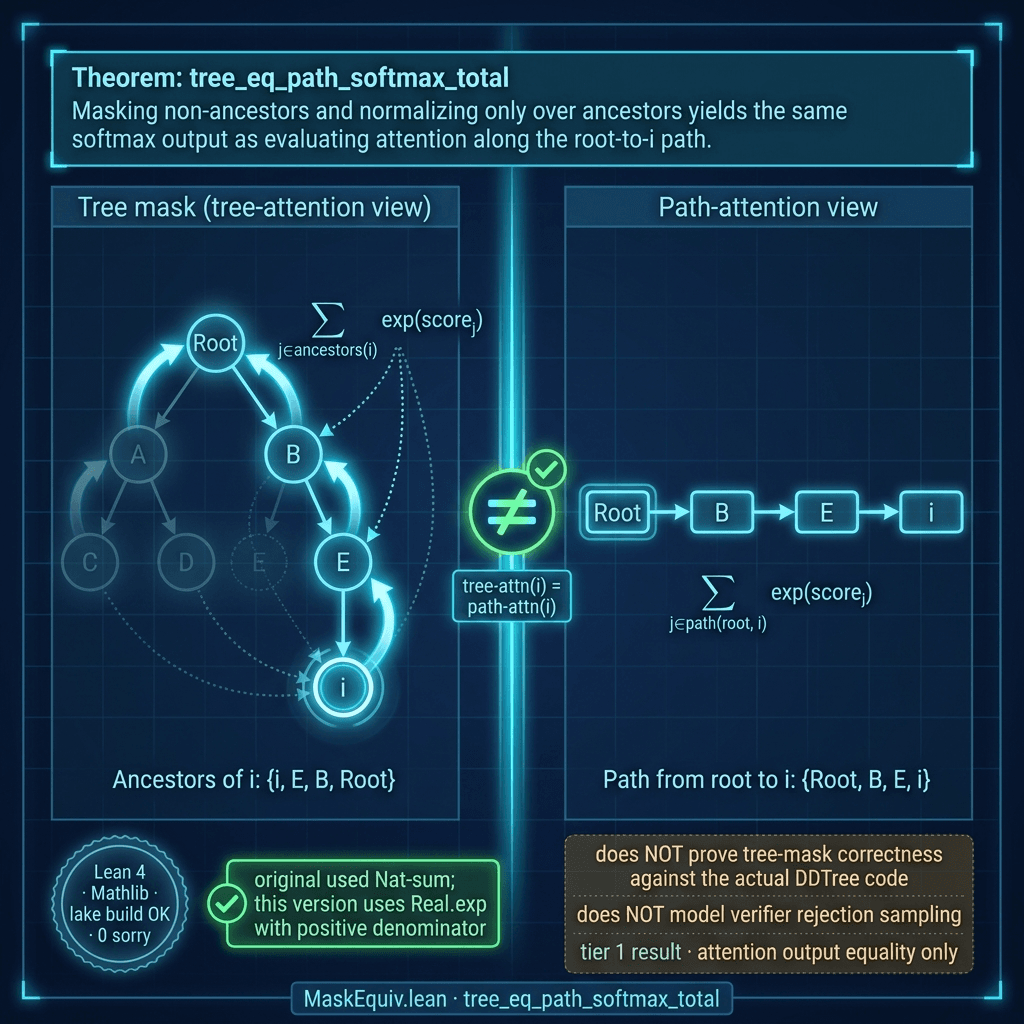
This one closes the audit's biggest overstatement. The original proved a filter-redundancy identity over List.range: set-theoretic, not numerical. The remediated version proves the headline a tree-mask softmax actually needs: at every query position, tree-attention output (softmax with mask zeroing non-ancestors) equals path-attention output (softmax over only the ancestor list), numerator and denominator separately, with the denominator strictly positive via the self-ancestor and Real.exp_pos. The obvious worry — masking inside the numerator while leaving the denominator unmasked could shift the softmax — is ruled out as a mathematical fact in ℝ.
👉 View source: MaskEquiv.lean
Two original Lean files were deleted, not relabelled
zerocopy.lean proved surface.region = surface.region after unfolding a transfer function defined to return its input's region field — no IOSurface API, no DMA, no concurrency. subsumption.lean proved a one-line modus-ponens specialization ((∀ p, IsPrefix p s → D p) → D s at p := s) — no probability, no Gemma model, no verifier algorithm, and could not back the "zero-hallucination" headline it had been carrying. Both deletions are documented in lean_remediation_notes.md §L4 and §L6.
4. Tier 2 — What TLA+ Can Model-Check (Under Bounds)
TL;DR: Like fuzz-testing a concurrent protocol, but exhaustive within a small bounded state space. TLC enumerates every reachable state and either finds a counter-example or doesn't. "No counter-example at 252 states" is real evidence — and explicitly not the same as a proof for unbounded inputs.
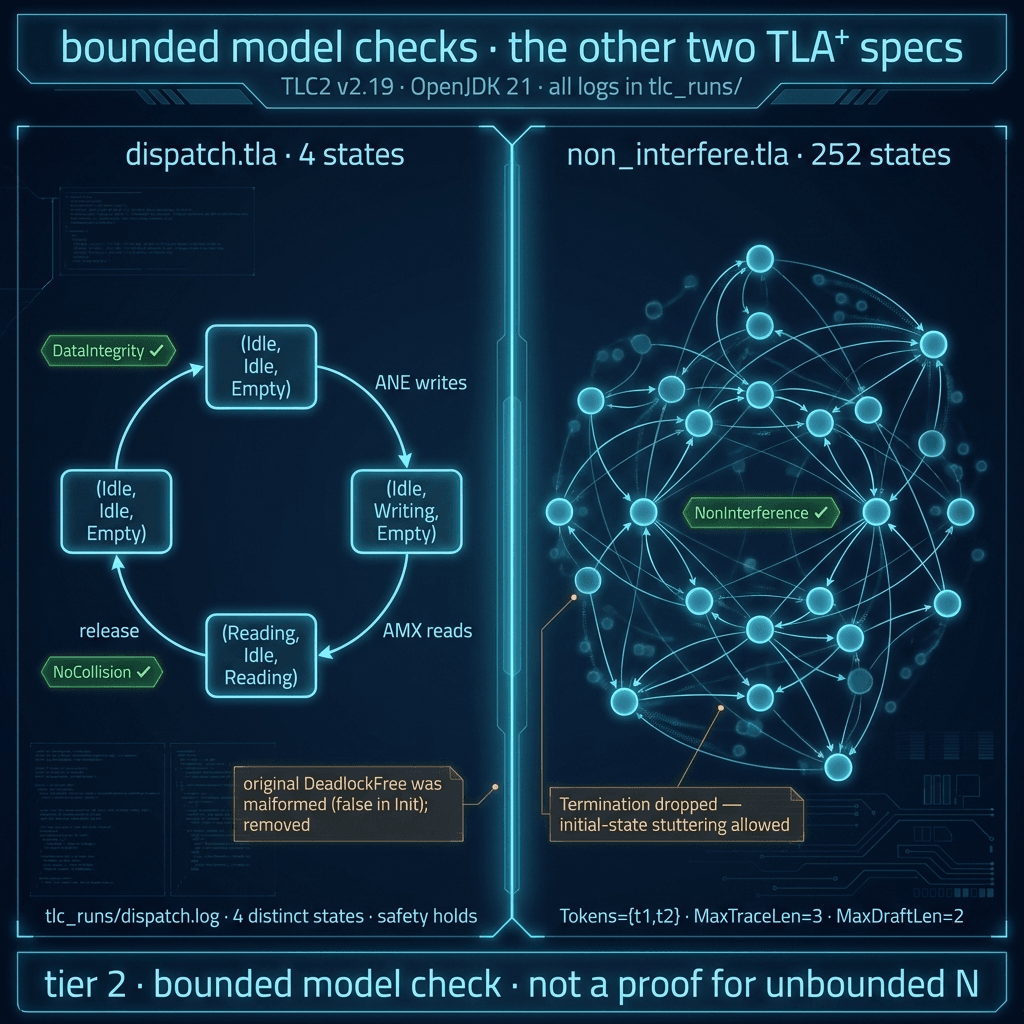
Toolchain: TLC2 v2.19 (8 Aug 2024) under OpenJDK 21.0.10, pinned in tla_toolchain.md. Bounded model checking is not a proof for unbounded N; every claim below carries the bound it was checked at.
| Spec | Property | Bound | States | Result | Log |
|---|---|---|---|---|---|
rollback.tla (Safe Spec) |
NoGhostReads (safety) |
MaxLen = 4 |
31 | no counter-example | rollback.log |
rollback.tla (UnsafeSpec) |
NoGhostReads (safety) |
MaxLen = 4 |
8 (search aborts at depth 4) | violated — 4-state counter-example | rollback_unsafe.log |
dispatch.tla |
DataIntegrity, NoCollision, Liveness == <>(buffer_state /= "Empty") under WF_vars(Next) |
(none) | 4 | no counter-example | dispatch.log |
non_interfere.tla |
NonInterference (safety only) |
Tokens = {t1, t2}, MaxTraceLen = 3, MaxDraftLen = 2 |
252 | no counter-example | non_interfere.log |
Three things worth pulling out of the table.
First, dispatch.tla is small: four states, three string-typed status variables. A hand-drawn diagram carries roughly the same evidence; TLC mostly serves as a parser and fairness-syntax check. The original spec shipped a DeadlockFree predicate written as ~(amx_status = "Idle" /\ ane_status = "Idle" /\ buffer_state = "Empty") — but that conjunction is exactly Init, so as an invariant it would fail in state zero. We removed it in remediation and replaced it with a salvaged Liveness under weak fairness. That removal is the kind of detail that decides whether you trust a verification report: any prior claim of "TLC verified safety" that included DeadlockFree could not have been green. See tla_remediation_notes.md §T2.
Second, non_interfere.tla shipped with Seq(Tokens) in Init, which TLC rejects as a non-enumerable quantifier bound — the shipped .tla + .cfg pair could not have produced any green output. The remediated version replaces Seq(Tokens) with a bounded helper BoundedSeq(S, N) == UNION { [1..n -> S] : n \in 0..N }, runs in 252 distinct states, and confirms NonInterference (defined as accepted_output is a prefix of target_model_trace) at the stated bounds. We dropped Termination because it is violated by initial-state stuttering and TLC's WF semantics on an action with an existential body don't force any particular witness; encoding a deterministic-drafter scheduler that nothing in the engineering pipeline actually uses would be less honest than dropping the property.
Third, the non_interfere invariant is structurally weaker than the noun phrase "non-interference" suggests. It says accepted_output is a prefix of a fixed target_model_trace chosen non-deterministically in Init. No probability, no sampling, no distribution. The honest title is "speculative-decoding prefix correctness, bounded TLC." Real probabilistic non-interference would live in Lean with MeasureTheory; we didn't get there.
We kept the original parse-failure logs in the repo as evidence of the pre-remediation state: rollback.parse-fail.log, dispatch.parse-fail.log, non_interfere.unbounded-fail.log.
👉 View source: dispatch.tla · non_interfere.tla · all tlc_runs/
5. Tier 3 — What ABS Can Illustrate (Behavioral Models)
TL;DR: Three executable pseudo-code models for cache and throughput behavior, each with
assertstatements that pin down the property the scenario is supposed to demonstrate. The original audit foundabscnot installed and ran nothing; this revision buildsabscfrom source on Apple Silicon and runs all three through the Erlang backend. The asserts now pass dynamically, on the captured scenarios — not as a proof for all inputs, but as a real green run with logs you can grep.
Three ABS files survive, with the framing demoted from "Verified" to "behavioral model — illustrates X; does not verify Y for all inputs." The original Track-A audit found absc not installed in this environment (no Homebrew formula; Docker pull inconclusive; source build deferred). The 2026-05-02 follow-up reverses that: absc was built from source against abstools/abstools master on Apple Silicon (steps and macOS-specific gotchas in reports/abs_toolchain.md), and all three files now compile through the Erlang backend, run via rebar3, and exit cleanly with their assertions firing. Captured stdout per file is in abs_runs/ — that's the upgrade from "by inspection" to "by execution."
Getting upstream master to actually produce a working absc on macOS / Erlang OTP 28 took three patches we filed against our local clone, checked in at patches/: (1) a Gradle task that replaces rebar3's priv symlink with a real directory before downstream tasks read it (macOS Gradle refuses to follow it), (2) a split of the rebar3 invocation into two passes — the first fetches deps and exits 1 per abstools/abstools#379, the second compiles absmodel and exits 0 — because the original ignoreExitValue = true masked the failure and shipped jars with zero absmodel .beam files (silent regression: deps' beams bundled, absmodel's not), and (3) migration of dpor.erl from the deprecated slave module (scheduled for removal in OTP 31) to the supported peer API. Without these three patches absc -e fails at the first model with Could not locate Runtime file:.../<module>.beam, and the "by execution" claim above isn't reproducible.
eml_ops.abs demonstrates the algebraic identity log(min(1, p/q)) = min(0, log p − log q) on one numeric pair (p=0.4, q=0.6). The captured run (abs_runs/eml_ops.log) reports sm = -0.4055, eml = -0.406, |diff| = 5.349e-4, and the assert diff < 0.001 passes. The file's latency = 24 and latency = 1 constants are explicitly labelled placeholders in the header — they encode a ratio narrative ("two log + sub vs one sub") rather than measured cycles. If a cycle-count claim ever appears in a benchmark post, it must come from a Metal microbenchmark or hardware counters, not from this file.
tree_perf.abs evaluates a closed-form throughput curve thr(B) = (log B + 1) / (10 + 0.5 B) at B ∈ {1,2,4,8,16,32,64} and asserts the discrete-grid argmax is at B = 8. The captured run (abs_runs/tree_perf.log) reports the per-B throughput and confirms argmax = 8 with thr(8) ≈ 0.21996. The MAL and latency curves are analytic guesses, not derived from a measured DDTree. The original file's // based on empirical logs comment was unsupported by any committed log and was removed in remediation.
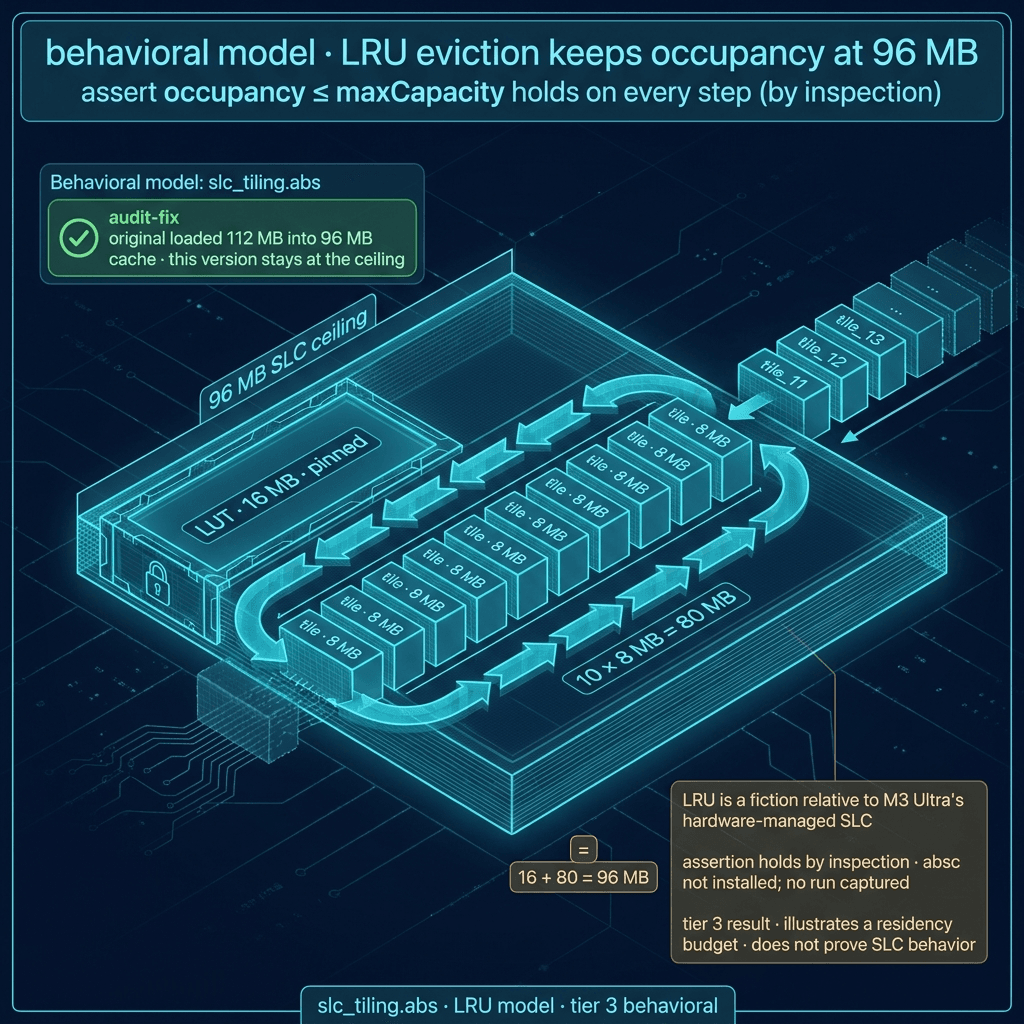
slc_tiling.abs is the most interesting demotion. The original scenario loaded 16 MB LUT + 12 × 8 MB tiles = 112 MB into a 96 MB cache and would have printed WARNING: DRAM Spill detected rather than the success the project plan claimed. We rewrote it with a pinned 16 MB LUT plus a 10-tile LRU budget (10 × 8 MB = 80 MB); streaming 12 tiles forces eviction of tiles 0 and 1 before tile 11 lands; re-accessing tile 0 is now a miss, re-accessing tile 11 is a hit. The captured run (abs_runs/slc_tiling.log) reports the full sequence of MISS / HIT / EVICT / LOAD events, ends at Final SLC Occupancy: 96MB / 96MB, and the assert occupancy <= maxCapacity after every access never fires. But the M3 Ultra SLC is a hardware-managed last-level cache with set-associative replacement closer to PLRU than strict LRU, so this artifact illustrates a residency invariant on a synthetic schedule rather than modelling the real cache. The honest verb is "demonstrated under one synthetic schedule" — Tier-3 ceiling.
👉 View source: eml_ops.abs · tree_perf.abs · slc_tiling.abs · patches/ (abstools build fixes)
6. Tier 4 — What's Left to Engineering
TL;DR: Performance numbers, NPU residency, zero-copy buffers — the things that actually show up in
powermetrics, Instruments, and benchmark logs. Deliberately out of scope here. If a claim only makes sense with a wall-clock measurement attached, it's not in this post.
The following are real claims about the runtime system. None of them is in the formal bundle. Their evidence lives in powermetrics, Instruments, and benchmark logs, not in Lean / TLA+ / ABS:
- Zero-copy
IOSurfacehandoffs between GPU and ANE. - ANE residency under Gemma 4 prefill (target
2–4 WNPU draw underpowermetrics). - Wall-clock
decode tok/s,prefill tok/s,total tok/s, andTTFSatW4 + FP16 KVandW4 + TQ 3.5-bit KV. - LUT FP4-to-FP16 SLC-resident dequantization speedup.
- GPU-attention ‖ ANE-MLP engine concurrency.
These are subject to standard verification rules: every speed claim from a wall-clock log; every residency claim from powermetrics; weight quantization and KV-cache quantization always labelled as independent axes. We make no perf claims here — that's what other posts on this blog are for (see Related Posts below). The point is that calling these "verified" because some file in the repo says theorem would be exactly the failure mode the audit caught.
7. What Formal Methods Can't Prove (The Most Interesting Half)
TL;DR: Nine concrete gaps between what we proved on paper and what actually runs in production. Floats aren't real numbers; abstract Lipschitz quantizers aren't TurboQuant; "no counter-example at 31 states" isn't a system-level proof; LRU isn't what Apple Silicon actually does. Each gap is its own paper-sized open problem.
This section is mandatory and longer than the verified ones, because the deferred findings are where the actual research questions live. Each item is a gap between Tier 1 / Tier 2 / Tier 3 evidence and the runtime system the prose is about.
1. Floats are not a commutative ring. Every Tier-1 theorem is stated over ℝ or a CommRing. Real Gemma 4 runs in bf16 / fp16: addition is not associative, multiplication has denormals, exp saturates at fp16's ~65 504 ceiling well before softmax overflows. None of RopeId, TQTopo, AttnIso, MaskEquiv transfer to IEEE-754 directly. The MaskEquiv denominator-positivity proof in particular uses Real.exp_pos, which has no analogue in fp16 once exp saturates. Closing this gap requires either a separate fixed-point error analysis showing backward-stable bounds, or a Mathlib-style formal float model. Neither is in scope here.
2. The Lean theorems prove things about interfaces, not Gemma-specific kernels. TQTopo proves a generic Lipschitz-perturbation bound for any T : V → V with ‖T z − z‖ ≤ η ‖z‖. The actual TurboQuant algorithm — Hadamard rotation, per-block scale, O(d^{-1/2}) probabilistic distortion — is unmodelled. AttnIso treats scores as abstract Nat → ℝ; the Q/K bilinear-form structure (score j = (Q · K_j) / sqrt(d)) is unmodelled. A reader who walks away saying "they proved TurboQuant on Gemma 4" is overstating; we proved that any η-Lipschitz quantizer is sound up to a Cauchy–Schwarz bound, and that any score function preserves SWA isolation when restricted to the window.
3. The TLA+ models reach 4, 31, 252 states. They are protocol skeletons, not system models. None of cache coherence, IOSurface lifetimes, partial writes, error paths, GPU-ANE memory ordering, sampling, KV-cache state, or AMX-vs-ANE memory-controller ordering appears in any of them. The right reading of Tier 2 is "no counter-example found in this finite slice," not "verified."
4. non_interfere.tla proves prefix-correctness, not probabilistic non-interference. The spec is parameterised by a fixed target_model_trace chosen non-deterministically in Init. The verifier action is the standard LCP-then-correction-token rule. Because every byte that lands in accepted_output is copied from target_model_trace, the NonInterference invariant is structurally near-tautological — it captures "the verifier's pseudocode is consistent with itself," not "the drafter cannot bias the distribution of the target." The latter would require Lean's MeasureTheory, a probabilistic drafter model, and an acceptance-rate argument. Different paper.
5. ABS still simulates one schedule, not all of them. A green absc run exhibits the asserted property for the scenario the program walks through — one numeric pair for eml_ops, one analytic grid for tree_perf, one LRU schedule for slc_tiling. ABS is not a model checker; it executes a single trace through the actor schedule. Promotion path to a real coverage claim would require either a TLA+-style state-space exploration of the same model or a property-based generator over input scenarios. The current Tier-3 floor is "the assertion holds on the committed scenario," not "for all inputs."
6. The slc_tiling.abs LRU is a fiction relative to the M3 Ultra SLC. Apple's SLC is a hardware-managed, set-associative last-level cache. We don't have its replacement policy from this codebase, and what we wrote — strict LRU with byte-counted occupancy — isn't it. The right artifact for "96 MB residency" is a powermetrics / Instruments residency trace under a real Gemma 4 prefill, not an ABS schedule. The remediated slc_tiling.abs now runs cleanly and its occupancy <= 96 MB assert holds on the captured scenario; "Proven 96 MB residency" was wrong, and the demoted phrasing is "demonstrated under one synthetic schedule with strict LRU eviction" — useful as a property-shape sanity check, not as evidence about real hardware.
7. Two original Lean files were deleted, not relabelled. zerocopy.lean proved surface.region = surface.region and modelled none of IOSurface, DMA, page tables, or driver state. subsumption.lean proved (∀ p, IsPrefix p s → D p) → D s instantiated at p := s — modus ponens dressed in LLM vocabulary, with no probability, no Gemma model, no verifier algorithm. Keeping either one with a "behavioral model" label would have continued to mislead readers who see theorem and trust it. The "zero-copy" and "zero-hallucination" claims are no longer Tier-1 deliverables of this project; they belong to engineering prose backed by runtime measurement, and that is where they go.
8. No Lean theorem is wired to a wall-clock or powermetrics measurement. The Tier-1 evidence supplies correctness properties of abstracted operators. It supplies zero performance evidence and zero hardware-residency evidence. Speed claims unsupported by wall-clock logs are out of scope for this post; every "+X% on Y-heavy kernels" line in the engineering documentation is Tier 4 and stays Tier 4.
9. Quantization labels are a runtime axis the formal bundle doesn't speak about. Weights and KV cache are independent quantization axes — W4 + FP16 KV is not the same configuration as W4 + TQ 3.5-bit KV, and "FP16 baseline" alone is a label that has caused at least one verdict re-write. The TQTopo theorem is about an abstract η-Lipschitz quantizer; matching it to a specific runtime configuration is something the engineering side has to do per benchmark. The formal artifacts speak in interface terms; the configuration matrix is future work.
8. Recap: What You Just Read
The three beats:
- The strongest evidence is a pair of runs, not a single green one. SafeRollback at 31 states with no counter-example, plus UnsafeRollback at 4 states with a concrete trace, together prove the
SafeRollbackguard is load-bearing. Either run alone would be borderline vanity; the pair is honest. - Tier 1 / 2 / 3 are not the same level of evidence. Lean theorems (mechanically rechecked,
lake buildexit 0, zerosorry) are stronger than TLA+ bounded model-checks (state counts 4 / 31 / 252; not proofs for unboundedN), which are stronger than ABS behavioral models (one schedule per file, run throughabscErlang backend, asserts pass on that schedule). The post labels each claim with its tier and never collapses the distinction. - The "(and can't)" half is the research roadmap. Floats vs
ℝ, generic interfaces vs Gemma-specific kernels, prefix-correctness vs probabilistic non-interference, ABS-one-schedule vs ABS-all-schedules, synthetic LRU vs hardware-managed SLC,theoremheaders vspowermetricstraces. Nine items, each its own paper.
9. Reproducibility
TL;DR: Clone the repo, run
lake buildand fourtlccommands, diff against the committed logs. Numbers mismatch means something drifted and the audit needs a re-run.
git clone https://github.com/atveit/InferenceAcceleration.git
cd InferenceAcceleration/g4-flashtree-formal-verification
# Lean — should print: "Build completed successfully (1980 jobs)"
elan toolchain install $(cat lean/lean-toolchain)
(cd lean && lake update && lake build)
diff <(tail -1 reports/lake_build.log) <(echo "Build completed successfully (1980 jobs).")
# TLA+ — TLC2 v2.19, OpenJDK 21
java -jar /path/to/tla2tools.jar -config tlaplus/rollback.cfg tlaplus/rollback.tla
java -jar /path/to/tla2tools.jar -config tlaplus/rollback_unsafe.cfg tlaplus/rollback.tla # expect counter-example
java -jar /path/to/tla2tools.jar -config tlaplus/dispatch.cfg tlaplus/dispatch.tla
java -jar /path/to/tla2tools.jar -config tlaplus/non_interfere.cfg tlaplus/non_interfere.tla
# ABS — absc built from source; see reports/abs_toolchain.md
for name in eml_ops tree_perf slc_tiling; do
rm -rf /tmp/abs_$name
absc -e -d /tmp/abs_$name abs/$name.abs
/tmp/abs_$name/run > abs_runs/$name.log 2>&1
done
diff abs_runs/eml_ops.log <(curl -s https://raw.githubusercontent.com/atveit/InferenceAcceleration/main/g4-flashtree-formal-verification/abs_runs/eml_ops.log)Expected outputs are checked in under reports/lake_build.log and tlc_runs/. If your local run diverges from those numbers (1980 jobs for Lean; 31 / 8 / 4 / 252 distinct states for the four TLA+ runs), something has drifted and the audit needs to be re-run.
Companion code: InferenceAcceleration/g4-flashtree-formal-verification/ bundles the surviving Lean / TLA+ / ABS files plus the captured TLC run logs in a single self-contained tree.
Related posts on this blog:
- Exp minus Log is all you need for Deep Learning? — the unified-EML substrate that the AttnIso and EML-ops models in this post are abstracting over.
- Can Prompt Lookup Decoding Speed Up Gemma 4 31B 4-bit on Apple Silicon for RAG-style Workloads? — the measurement-driven companion to this formal-methods post: parity scoreboards, wall-clock numbers, and the engineering-side counterpart to the rollback / non-interference properties modelled here.
Appendix I: Surviving Artifacts
| Tier | File | Purpose | TLDR | Link |
|---|---|---|---|---|
| 1 | RopeId.lean |
Lean 4 theorem | Rotation (c, s) with c² + s² = 1 preserves the dot product over a CommRing. |
Code |
| 1 | TQTopo.lean |
Lean 4 theorem | Inner-product distortion bounded by 2η‖x‖‖y‖ + η²‖x‖‖y‖ for any η-Lipschitz T. |
Code |
| 1 | AttnIso.lean |
Lean 4 theorem | SWA softmax-attention is zero-leakage; agreement inside the window implies equal outputs incl. denominator. | Code |
| 1 | MaskEquiv.lean |
Lean 4 theorem | tree_eq_path_softmax_total: tree-mask softmax equals path-attention with denominator over ancestors. |
Code |
| 2 | rollback.tla |
TLA+ spec | Safe-vs-unsafe rollback. Two configs: Safe holds at 31 states; Unsafe produces a 4-state counter-example. | Spec · Safe.cfg · Unsafe.cfg |
| 2 | dispatch.tla |
TLA+ spec | 4-state dispatch protocol; DataIntegrity and NoCollision hold; DeadlockFree removed (was false in Init). |
Spec · .cfg |
| 2 | non_interfere.tla |
TLA+ spec | Speculative-decoding prefix-correctness against a fixed target trace; 252 states; Termination dropped. |
Spec · .cfg |
| 3 | eml_ops.abs |
ABS behavioral model | Softmax↔Min-Plus parity on one pair (p=0.4, q=0.6); assert diff < 0.001 passes (` |
diff |
| 3 | tree_perf.abs |
ABS behavioral model | Closed-form throughput sweep over B ∈ {1..64}; assert optimalB == 8 passes (thr(8)≈0.21996). |
Code · Run log |
| 3 | slc_tiling.abs |
ABS behavioral model | LRU cache demo: 16 MB pinned LUT + 10×8 MB tiles = 96 MB ceiling; assert occupancy ≤ maxCapacity passes at every access (peak occupancy = 96 MB). |
Code · Run log |
Appendix II: Audit & Remediation Trail
| File | Purpose | Link |
|---|---|---|
audit_lean.md |
Original Lean audit | Found 2/6 files non-compiling, 4 sorrys, 2 vacuous proofs; verbatim lean output captured. |
audit_tla_abs.md |
Original TLA+ / ABS audit | Found 2/3 TLA+ specs unparseable, the third's shipped .cfg non-runnable, the SLC ABS contradicting its own claim. |
REMEDIATION_PLAN.md |
Four-tier strategy | Defines Tier 1/2/3/4 evidence pyramid and the L/T/A/R track structure used to remediate. |
lean_remediation_notes.md |
Track L log | Lakefile + Mathlib bootstrap; sorry discharge; zerocopy.lean and subsumption.lean deletion rationale. |
tla_remediation_notes.md |
Track T log | Comment-syntax and module-import fixes; BoundedSeq helper for non_interfere; per-spec self-critique. |
abs_remediation_notes.md |
Track A log | slc_tiling arithmetic fix; asserts added; honest demotion from "Verified" to "Behavioral model." |
final_synthesis.md |
Track R synthesis | Tier-classified write-up after L/T/A landed. |
track_r_notes.md |
Track R log | Cross-document consistency check; nine-caveat matrix; OVERVIEW + plan rewrite. |
⚠️ Disclaimer: Audited-before-publish formal-methods write-up of a hypothetical Gemma 4 + DFlash + DDTree speculative-decoding stack on Apple Silicon. Two parallel audits found that several originally-claimed artifacts were either non-compiling, unparseable, or mathematically vacuous. This post documents only what survived a four-tier remediation pass. No performance claims. The "(and can't)" half is the most interesting half.