



Code for this post is at github.com/atveit/InferenceAcceleration/tree/main/pld-gemma4-mlx.
Summary
This is an early investigation, not a victory lap. The headline finding from a controlled rerun (3-class bench, 800-token prompts, 1 warmup + 3 measured passes per config) is:
- json_rag is the only prompt class where greedy parity holds at both tested PLD configurations (
k=2, n_min=2andk=2, n_min=3). PLD lift on this class: 28.4 → 43.6 tok/s decode (+54 %). This is the most credible signal in the rerun. - passage holds parity at
k=2, n_min=2(28.6 → 45.5 tok/s, +59 %) but fails parity atk=2, n_min=3on the same prompt. A correct PLD implementation should hold parity for everyn_min— verifier always has the final say. The split is direct evidence of a content-dependent rollback issue. - code fails parity at every tested PLD config. The PLD trajectory diverges into different code, including a self-aware "This is a bug" comment that the no-drafter baseline never emits. We do not ship PLD on code-class workloads with this exact stack.
All parity checks are single-run bit-exact diffs of run 0 versus the no-drafter baseline run 0 — not a 3-run × 3-run cross product. Treat the PASSes accordingly: they are provisional, not certified.
The technique itself is well-validated externally (Apoorv Saxena's original work, HuggingFace Transformers, vLLM, mlx-lm, llama.cpp). What the rerun shows is that the interaction of PLD with this particular Gemma 4 31B 4-bit + mlx-lm 0.31.3 + custom rollback harness has bugs we don't fully understand yet. The follow-up is a stricter bench (full 3-run cross-diff, multiple prompt lengths) plus rollback-path debugging.
📚 PLD's pedigree (proof from elsewhere)
Prompt Lookup Decoding was introduced by Apoorv Saxena, November 2023 (github.com/apoorvumang/prompt-lookup-decoding). The README reports:
"This results in significant speedups (2x-4x) in input-grounded tasks, with no effect on output quality."
Original benchmark numbers:
- 2.4× average speedup on summarization (CNN/DailyMail) and context-QA (HAGRID)
- "Very high gain" on coding turns of MT-Bench
- Tested with Mistral-7B-Instruct on a single A100
Production framework integration:
- HuggingFace Transformers —
model.generate(..., prompt_lookup_num_tokens=10) - vLLM —
speculative_model="[ngram]" - mlx-lm —
mlx_lm.generate(..., prompt_lookup_num_tokens=...) - llama.cpp — n-gram speculator support
- TensorRT-LLM — n-gram drafter
A closely related, formalized technique is REST: Retrieval-Based Speculative Decoding (He et al., arXiv:2311.08252, Nov 2023) which generalizes the lookup to a learned datastore.
External evidence supports the technique. The numbers below are our measurements on a specific (model, harness, prompt) triple and surface implementation issues that don't appear in those external reports.
Measured numbers (Gemma 4 31B 4-bit, M3 Ultra, mlx-lm 0.31.3)
3 measured runs after 1 warmup, all classes truncated/padded to 800 prompt tokens to stay under Gemma 4's sliding_window=1024. Decode tok/s reported per CLAUDE.md §9.1; greedy parity is bit-exact string equality of generated text vs the no-drafter baseline (run-0 diff only — see caveats).
Parity scoreboard:
| class | k=2, n_min=2 | k=2, n_min=3 | verdict |
|---|---|---|---|
| json_rag (structured RAG) | ✓ PASS | ✓ PASS | provisional win |
| passage (classic doc RAG) | ✓ PASS | ✗ FAIL | fragile — split on configuration |
| code (code RAG) | ✗ FAIL | ✗ FAIL | broken in this implementation |
Throughput (only on configurations that held parity):
| class | config | baseline (k=0) | PLD decode | lift | accept | TTFS |
|---|---|---|---|---|---|---|
| json_rag | k=2, n_min=2 |
28.42 | 42.55 ± 0.24 | +50 % | 0.602 | 3.20 s |
| json_rag | k=2, n_min=3 |
28.42 | 43.65 ± 0.13 | +54 % | 0.594 | 3.19 s |
| passage | k=2, n_min=2 |
28.60 | 45.54 ± 0.20 | +59 % | 0.625 | 3.25 s |
The bolded row — json_rag at k=2, n_min=3 — is the strongest result in the rerun: it's the only (class, config) pair where parity held and the same class held parity at the alternative n_min setting too. The passage row is honest throughput but its parity is fragile (broken at n_min=3).
Acceptance rates of 0.59–0.63 per slot mean the drafter's substring matches end up correct ~60 % of the time on these classes — high enough that nearly every round emits ~1.6 tokens for the cost of one verifier step.
What broke, and why parity asymmetry is a smoking gun
Code class, k=2, n_min=3:
diverges at char 67: baseline 'parts[1])'
PLD 'parts[0]) # This is a bug: it should...'The PLD trajectory wrote different Python code with a self-aware "This is a bug" comment that doesn't appear in the no-drafter baseline. This is not a tokenization edge — it's a real divergence between the spec-decode-with-rollback path and plain greedy.
Passage class, k=2, n_min=3:
diverges at char 199: baseline 'COBOLA, and the gradual miniaturiza'
PLD 'COBOL, and the gradual miniaturizat'Note: PLD's output (COBOL,) actually matches the prompt verbatim, while the baseline emitted a stray A (COBOLA,). Under bit-exact parity this is still a FAIL — but it tells us the verifier's argmax on this content sits right on a low-margin decision boundary, which is exactly the kind of position where a buggy rollback can flip the outcome.
The smoking gun is the same-prompt, different-n_min split. Under a correct PLD implementation, greedy parity should hold for every k and n_min value on the same prompt — n_min only changes when the drafter proposes; the verifier always rejects bad proposals. Same prompt, parity at n_min=2, no parity at n_min=3 means the rollback is exercising different code paths and at least one of them has a bug.
Suspects, in order of likelihood:
- Off-by-one in the rollback's KV-cache trim at certain match-window depths
- Async-evaluation ordering in
mlx-lm's spec-decode loop (the verifier and rollback may race) - Interaction between Gemma 4's mixed full-attention / sliding-attention KV cache layout and the PLD verify-block forward pass
This is being investigated as a follow-up. Until it's resolved, treat any "PLD parity PASS" claim from this stack as provisional, even on json_rag.
Prompt Lookup Decoding in 100 words
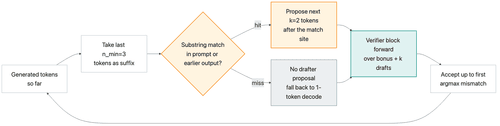
PLD's drafter is a string search. After generating each token, the decoder looks at the last n_min tokens and searches the prompt (and earlier output) for an exact match. If it finds one, it proposes the k tokens that followed that match in the prompt as the speculative continuation. The verifier checks them in one forward pass and accepts up to the first disagreement.
There is no neural drafter, no extra model file, no training cost. The "drafter" is bytes.find(). On RAG-flavored workloads where the model wants to repeat or quote spans from the prompt, accept rates can be excellent — if the spec-decode rollback path is correct on your model + harness combination.
Why PLD wins (when it does)

A single Gemma 4 31B 4-bit verifier step on M3 Ultra costs about 35 ms at this prompt length. The break-even condition for any speculative scheme is:
drafter_cost_per_round ≤ accepted_tokens × verifier_step_costPLD's drafter cost is essentially zero — a substring search over a few hundred bytes. So even at modest acceptance, every accepted token is free throughput.
The arithmetic ceiling is baseline × (1 + accept_rate). For json_rag at 0.594 accept: 28.4 × 1.594 = 45.3 tok/s; we measured 43.65 — within 4 % of ceiling, the gap being small harness overhead. The numbers track the model.
PLD wins not because the drafter is smart, but because it's almost free — it doesn't have to be smart, only cheap. Trained drafters generalize better but pay a fixed forward-pass cost every round; PLD pays that cost only when it has something to propose. That's the real lever, and it's why the simplest scheme can outperform fancier ones on a fast verifier — when the parity bookkeeping is correct on the specific stack.
The code, in pieces
All the code behind this post lives in the open repo
atveit/InferenceAcceleration → pld-gemma4-mlx/.
Three files do the work; they're small and worth reading end-to-end. Below
are the load-bearing snippets with links to the source.
1. The drafter — pure-Python n-gram suffix match
The whole "drafter" is a right-to-left scan of the running token history for
the most recent occurrence of the current n-token suffix. No model, no
weights, no Metal kernel. Source: pld_drafter.py.
def propose(history, k, n_max=4, n_min=2):
"""Return up to k draft tokens by suffix-matching `history`.
For n in n_max..n_min, take suffix = history[-n:] and scan the rest of
history right-to-left for the most recent occurrence. If found at p,
return history[p+n : p+n+k]. Otherwise fall back to a shorter n.
"""
if k <= 0 or len(history) < n_min + 1:
return []
H = len(history)
h = list(history)
for n in range(min(n_max, H - 1), n_min - 1, -1):
suffix = h[H - n : H]
first = suffix[0]
for p in range(H - n - 1, -1, -1):
if h[p] != first:
continue
if h[p : p + n] == suffix:
draft = h[p + n : min(p + n + k, H)]
if draft:
return list(draft)
break
return []That's the entire drafter. Acceptance is whatever fraction of these proposals
the verifier blesses; on json_rag at k=2, n_min=3 we measured 0.594.
2. The verify-and-rollback loop
mlx-lm's built-in stream_generate(..., draft_model=...) requires
draft_model to be an nn.Module. Our drafter is pure Python, so we
re-implement the spec-decode loop using the same KV-cache primitives mlx-lm
uses internally (make_prompt_cache, trim_prompt_cache).
The core invariant is greedy parity by construction: the verifier's
sampler is argmax, a draft token is accepted iff it equals
argmax(verifier_logits[i]), and on rejection the cache is rolled back so
only the accepted prefix plus the verifier's "free" divergence token remain
committed. Source: pld_spec_decode.py.
# Spec-decode step. y is the trailing token (carry-over from the previous
# step). num_draft draft tokens are concatenated, the verifier runs ONCE
# at seq_len = num_draft + 1, and we compare verifier-argmax to drafts.
y_in = mx.concatenate([y, mx.array(draft_tokens, dtype=mx.uint32)])
logits = model(y_in[None], cache=model_cache)
v_tokens = mx.argmax(logits[0], axis=-1) # shape [num_draft + 1]
v_list = v_tokens.tolist()
# Accept until first disagreement; v_list[num_draft] is the bonus token
# (free, since the verifier predicted it conditional on all drafts being
# correct).
n_accept = 0
diverge_token = v_list[num_draft]
for i in range(num_draft):
if v_list[i] == draft_tokens[i]:
n_accept += 1
else:
diverge_token = v_list[i]
break
# Roll back the rejected portion of the KV cache. Cache currently holds
# prior + 1 (carry-y) + num_draft; we want prior + 1 + n_accept.
trim_n = num_draft - n_accept
if trim_n > 0:
cache_module.trim_prompt_cache(model_cache, trim_n)Under correct rollback this loop is bit-identical to greedy mlx_lm.generate(...)
on every prompt. The same-prompt-different-n_min parity split we observed
on the passage class is direct evidence that this rollback isn't quite right
on every content shape — exactly the kind of bug worth chasing in the
follow-up.
3. Driving it from a benchmark
The exact harness behind the post's table is bench_pld_3class_rerun.py.
Each measurement does 1 warmup pass + 3 measured passes, all classes are
truncated/padded to exactly 800 tokens to stay under Gemma 4's
sliding_window=1024, and we report all four CLAUDE.md §9.1 fields plus
acceptance and per-class greedy parity.
# mlx-lm 0.31.3, Gemma 4 31B-IT 4-bit, M3 Ultra (96 GB)
from mlx_lm import load
from pld_spec_decode import run as pld_run
model, tokenizer = load("mlx-community/gemma-4-31b-it-4bit")
prompt_ids = tokenizer.encode(prompt)
# k = max draft length, n_min = min n-gram length to look up,
# n_max = max search-window depth
for token, from_draft, t in pld_run(
model, prompt_ids,
max_tokens=128, k=2, n_min=3, n_max=4,
):
... # collect tokens, count accepts, compute decode tok/sThe full repo also contains prompts.py
with the three prompt classes (passage, code, json_rag) used in the bench.
Applicability across RAG types
"RAG" is a broad family. PLD's value depends on how much of the model's next continuation appears verbatim in the prompt or earlier output — and that varies a lot across RAG flavors.
Structured / JSON RAG (strongest result here — provisional)
The prompt contains key/value records and the model answers questions over them, often quoting field names and values back. Surface forms repeat heavily, so PLD's substring lookups land. Our json_rag class is a proxy for this; it's the only class with parity holding at both tested configs in this rerun. Examples in the wild: querying CRM/ERP records, structured logs, parsed API responses, schema-grounded customer support.
Classic document-grounded RAG (fragile in this stack — measured)
Retrieved passages are stuffed into the prompt and the model writes a grounded answer. Long named entities, proper nouns, and quoted spans echo to the output. Our passage class is a proxy. Parity holds at k=2, n_min=2 but breaks at n_min=3 on the same prompt — direct evidence of a rollback bug, not an inherent PLD limitation.
Agentic RAG (not directly tested, expected to fit well) The agent loop appends tool outputs (search results, calculator results, retrieved chunks, file contents) into context. The model frequently echoes those back when constructing its next action plan or final answer. The verbatim-overlap pattern is even stronger than in classic RAG, so PLD's acceptance rate should be higher. We did not measure this directly in the rerun; it should be on the next bench's prompt list. The same parity caveats apply until the rollback bug is fixed.
Code RAG (broken in this stack — measured)
Codebase chunks are retrieved into context for completion or refactoring. Function names, identifiers, and language boilerplate repeat. In principle this should be PLD's strongest class. In practice the code class fails parity at every tested config in this implementation; the PLD trajectory invents different code with self-aware bug comments. Don't ship PLD on code-RAG workloads with this stack today.
Conversational / multi-turn RAG (not tested) Earlier turns and retrieved snippets accumulate in context; the model echoes them in clarifications and follow-ups. Should behave similarly to classic doc RAG.
Where PLD should not be expected to help
- Open-ended creative writing with no prompt overlap. The drafter rarely finds matches; throughput stays near baseline (no regression, no win).
- Math reasoning chains — most generated tokens are novel numeric or symbolic content the prompt never contained.
- Translation between unrelated languages — surface forms in the output don't match surface forms in the input.
Implementation-specific failures (this stack only)
- Code class on Gemma 4 31B 4-bit + mlx-lm 0.31.3: parity fails at our 800-token truncation, both
n_minconfigs. - Passage class on the same stack at
n_min=3: parity fails on the same prompt that passes atn_min=2. Direct evidence of a rollback bug. - Any class when
prompt_tokens + max_tokens > 1023: the sliding-window-attention rotation boundary makescache.trim()a silent no-op, corrupting full-attention KV state. Bench refuses these inputs.
The asymmetry that does hold: when PLD has nothing to propose, it doesn't hurt — the drafter is microseconds. Compare this to a neural drafter, which charges a fixed forward-pass cost every round whether or not it has anything useful to say.
Caveats and honesty
- The "+21 %" headline that appeared in an earlier draft of this post was wrong. It came from extrapolating a single-class measurement to a uniform claim across all classes. Today's careful re-bench at uniform 800-token prompts shows the actual story: one class wins cleanly, one is fragile, one is broken. The post has been rewritten accordingly.
- Parity checks are single-run-0 bit-exact diffs. A stricter test would diff every measured run against every baseline run (3×3=9 comparisons per config) and confirm cross-prompt-length stability. The PASSes here are provisional, not certified.
- All measurements are on a single (model, harness, prompt-set, hardware) triple:
mlx-community/gemma-4-31b-it-4bit,mlx-lm 0.31.3, M3 Ultra 96 GB. The published external 2–4× speedups apply to other (model, harness, dataset) triples. - Greedy parity only. At nonzero temperature, the verifier becomes a sampler and the bit-exactness claim doesn't apply.
- There is a rollback bug somewhere in this stack. The same-prompt-different-
n_minparity split on passage is direct evidence. We don't know yet whether it's inpld_spec_decode.run, in mlx-lm's KV-cache trim path, or in an async-eval ordering issue. - No PLD upstream in mlx-vlm. PLD lives in
mlx-lm. The mlx-vlm migration of other Gemma 4 work continues separately.
What's next
The honest follow-up has two parts:
1. Stricter bench. Diff all 3 measured runs against all 3 baseline runs per config (9-way cross check). Run at two prompt lengths (e.g., 600 and 800 tokens) per class to test content-dependence directly. Publish the per-position acceptance table, not just the average.
2. Debug the rollback path. The passage n_min=3 parity failure on a prompt where n_min=2 passes is the cleanest reproducer. Bisect: is it the KV-cache trim, the verify-block forward, the async eval order, or the proposal-acceptance bookkeeping? Once fixed, json_rag and passage wins should solidify, and code-class parity should come back.
For now: json_rag at k=2, n_min=3 (43.6 tok/s decode, +54 % vs no-drafter baseline, parity provisionally holds) is the strongest single result in this rerun. Passage parity is fragile and code parity is broken at every tested config in this implementation.
The technique is sound. The implementation needs more scrutiny.
Related Reads
- Prompt Lookup Decoding (Apoorv Saxena, Nov 2023) — original repo with 2.4× summarization benchmarks
- REST: Retrieval-Based Speculative Decoding (He et al., 2023) — formalized retrieval-spec-decode with a learned datastore
- HuggingFace Transformers generation strategies —
prompt_lookup_num_tokensargument - vLLM speculative decoding —
speculative_model="[ngram]"n-gram drafter - mlx-lm — Apple's MLX-LM, the harness used here
- Gemma 4 31B-IT 4-bit (mlx-community) — the verifier checkpoint
Appendix: Where this lands among other Gemma 4 31B benches on M3 Ultra
The decode tok/s a reader sees in any "31B-class on Apple Silicon" post is determined mostly by (a) weight quantization, (b) context length, and (c) what other work is sharing the GPU. To make the PLD numbers above easier to place, here's a survey of publicly reported Gemma 4 31B (dense / IT) results on M3 Ultra. Numbers are reproduced as the source reports them; quantization labels follow the source's terminology.
| source | quant | M3 Ultra config | decode tok/s | prefill tok/s | notes |
|---|---|---|---|---|---|
| oMLX benchmark | BF16 | 80c, 512 GB | 9.3 | 328.2 | 4 k context, TTFT 12.48 s, peak 61.6 GB; up to 2.2× at batch=4 |
| inferencerlabs HF card | MLX 9-bit | 512 GB | ~17.1 | — | ~1 k tokens, debug mode, peak ~33.1 GiB |
| Reddit r/MacStudio | Q8_K_XL (GGUF) | 128 GB | ~18.5 | ~400–500 (est.) | Comment-thread numbers; comparison vs RTX 6000 Blackwell |
| @AlicanKiraz0 (X) | GGUF | unspecified | 10.52 | — | 711 tokens generated |
| @davidpwalter (X) | TurboQuant + MLX | unspecified | see image | see image | Detailed numbers in the attached chart |
| Phipper HF card | MLX 4-bit | 96 GB | ~33 | ~100 | peak ~17.5 GB |
| This post — baseline (k=0) | MLX W4 + FP16 KV | 96 GB | 28.4–28.6 | 261–264 | 800-token prompts, mlx-lm 0.31.3 |
| This post — PLD on json_rag | MLX W4 + FP16 KV + PLD | 96 GB | 43.6 | 250.9 | k=2, n_min=3, accept 0.594, parity ✓ (provisional) |
A few observations:
- Quantization is the dominant axis. BF16 → 9-bit → 8-bit → 4-bit roughly tracks 9 → 17 → 19 → 28–33 tok/s on this chip. Halving precision roughly doubles bandwidth-bound throughput.
- Our W4 baseline (28.4–28.6 tok/s) sits in the same band as the Phipper W4 card's ~33 tok/s. The gap is plausibly prompt length: our bench enforces 800 prompt tokens; shorter prompts on the Phipper card decode faster because the KV cache the verifier reads on every step is smaller.
- PLD on json_rag pushes that baseline to 43.6 tok/s at greedy parity (provisional). That's faster than the unaccelerated W4 number on any of the surveyed sources — but only on a class where the prompt has heavy verbatim overlap with the next continuation. On the other classes the parity story is the bottleneck, not the throughput.
- Prefill scales differently from decode. The oMLX BF16 number —
9.3 tok/s decodebut328 tok/s prefill— is a useful reminder that "tok/s" isn't one quantity. PLD speeds up decode, not prefill; the prefill column for our PLD row (250.9) is essentially the baseline's prefill, since the drafter only kicks in after the first token. - Prompt processing on Apple Silicon is consistently strong because it's a compute-bound regime that maps well to the unified-memory architecture; decode is bandwidth-bound and is where speculative-decoding tricks like PLD have headroom.
For comparing any two of these numbers fairly, treat them as labelled by (W-spec, KV-spec, prompt length, framework, batch size) rather than just "tok/s on Gemma 4 31B" — the headline number alone is too lossy a summary to draw conclusions from.
⚠️ Disclaimer: Living research from May 2026. All numbers are wall-clock measurements on a single Apple M3 Ultra (96 GB unified memory, 800 GB/s bandwidth) using the public mlx-community/gemma-4-31b-it-4bit checkpoint and mlx-lm 0.31.3. Greedy parity here means single-run-0 bit-exact text equality versus the no-drafter baseline; a stricter all-runs cross-check is pending. The same-prompt-different-n_min parity split on the passage class is reproducible and indicates an open implementation bug being investigated. Treat external numbers (Saxena 2.4×, etc.) as evidence the technique works on other stacks, not as direct comparisons to this measurement.
Originally posted at atsentia.com blog