


mojo-vec brings Rust-style zero-copy buffer performance to Mojo — inline storage, pointer-based slicing, and SIMD operations.
Mojo's List[T] heap-allocates every instance and copies data for slices. For BPE tokenization (100+ slices per encode), this creates overhead. mojo-vec fixes this.
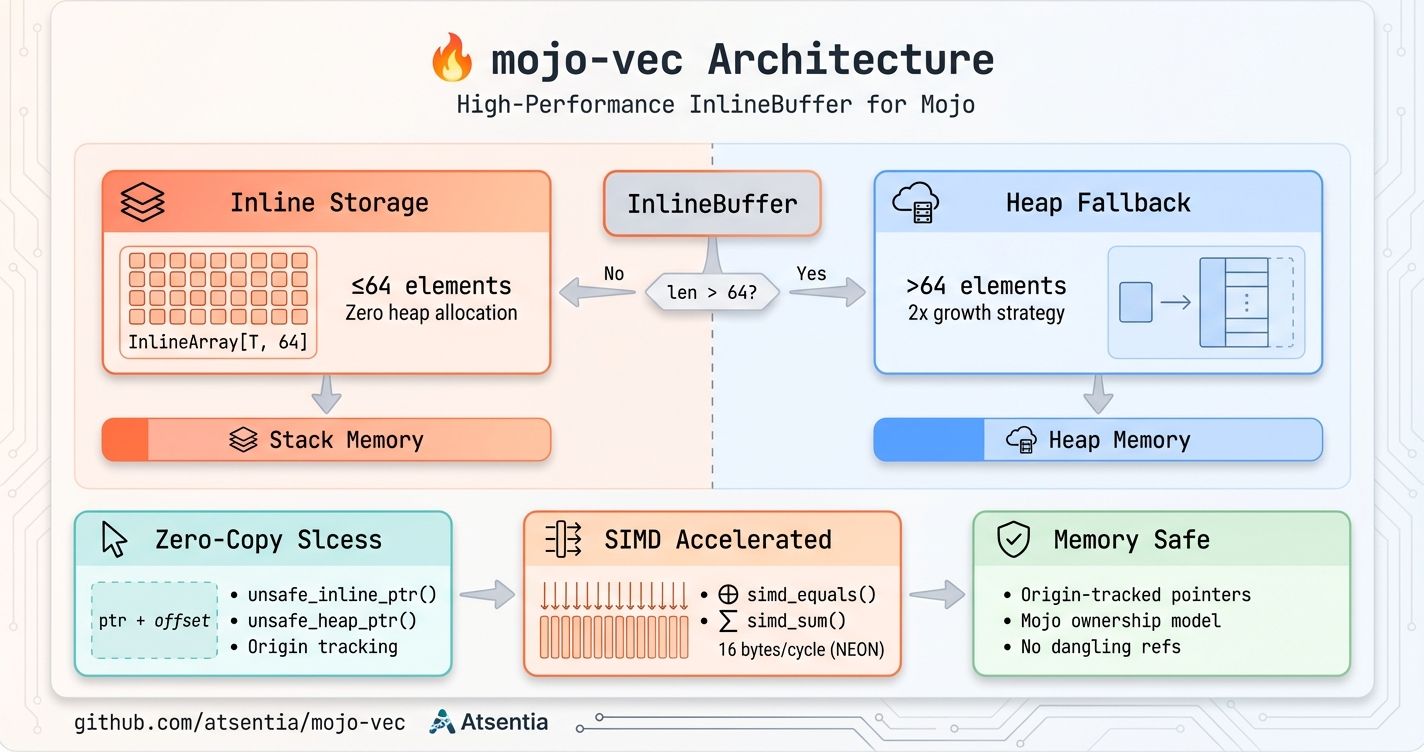
The Architecture
mojo-vec provides InlineIntBuffer and InlineByteBuffer — hybrid buffers with two storage modes:
| Mode | Capacity | Allocation | Use Case |
|---|---|---|---|
| Inline | ≤64 elements | Stack (zero heap) | Token sequences, small arrays |
| Heap | >64 elements | Heap (2x growth) | Large buffers |
var buf = InlineByteBuffer()
for i in range(64):
buf.append(UInt8(i)) # All on stack — no heap allocation!
buf.append(UInt8(64)) # 65th element triggers heap fallback
print(buf.is_inline()) # FalseZero-Copy Slice Access
The key innovation: pointer-based slicing instead of copying.
# Get raw pointer for zero-copy access
var ptr = buf.unsafe_inline_ptr() if buf.is_inline() else buf.unsafe_heap_ptr()
# Zero-copy slice via pointer arithmetic
var pos = 50
var remaining = ptr + pos # No allocation, no copy!
print(remaining[0]) # Direct memory accessThis matches Rust's &[T] slice semantics. For BPE tokenization's inner loop:
# BEFORE: Mojo List (allocates every iteration)
var remaining = List[UInt8](capacity=len(text) - pos)
for i in range(pos, len(text)):
remaining.append(text[i]) # O(n) copy per lookup
# AFTER: InlineBuffer (zero-copy)
var remaining = ptr + pos # O(1) pointer arithmeticSIMD Operations
InlineByteBuffer includes SIMD-accelerated methods using ARM NEON:
# SIMD-accelerated equality (16 bytes per cycle)
if buf1.simd_equals(buf2):
print("Equal")
# SIMD-accelerated sum
var total = buf.simd_sum() # 4x faster than scalarThe comparison uses XOR + reduce pattern:
- Load 16 bytes from each buffer
- XOR the chunks (equal bytes → 0)
reduce_add()on result (0 = all bytes equal)- Cast to UInt32 before reduce to avoid overflow
Why Two Pointer Methods?
Mojo's origin tracking requires separate methods for inline and heap storage:
fn unsafe_inline_ptr(ref [_] self) -> UnsafePointer[UInt8, origin_of(self._inline)]:
return self._inline.unsafe_ptr()
fn unsafe_heap_ptr(ref [_] self) -> UnsafePointer[UInt8, origin_of(self._heap)]:
return self._heap.unsafe_ptr()The origin_of() return type ties the pointer's lifetime to the correct field, preventing dangling references. This is Mojo's answer to Rust's borrow checker.
When to Use
| Workload | Benefit |
|---|---|
| BPE tokenization | Eliminates 100+ allocations per encode |
| Byte buffer parsing | Zero-copy slice views |
| Small fixed arrays | Stack allocation (no heap) |
| SIMD byte operations | 16x faster comparison |
Try It
git clone https://github.com/atsentia/mojo-vec
cd mojo-vec
mojo run -I . tests/test_inline_buffer.mojo # 21 tests
mojo run -I . benchmarks/bench_comparison.mojo # BenchmarksPart of the mojo-contrib ecosystem.
Originally posted at atsentia.com blog