


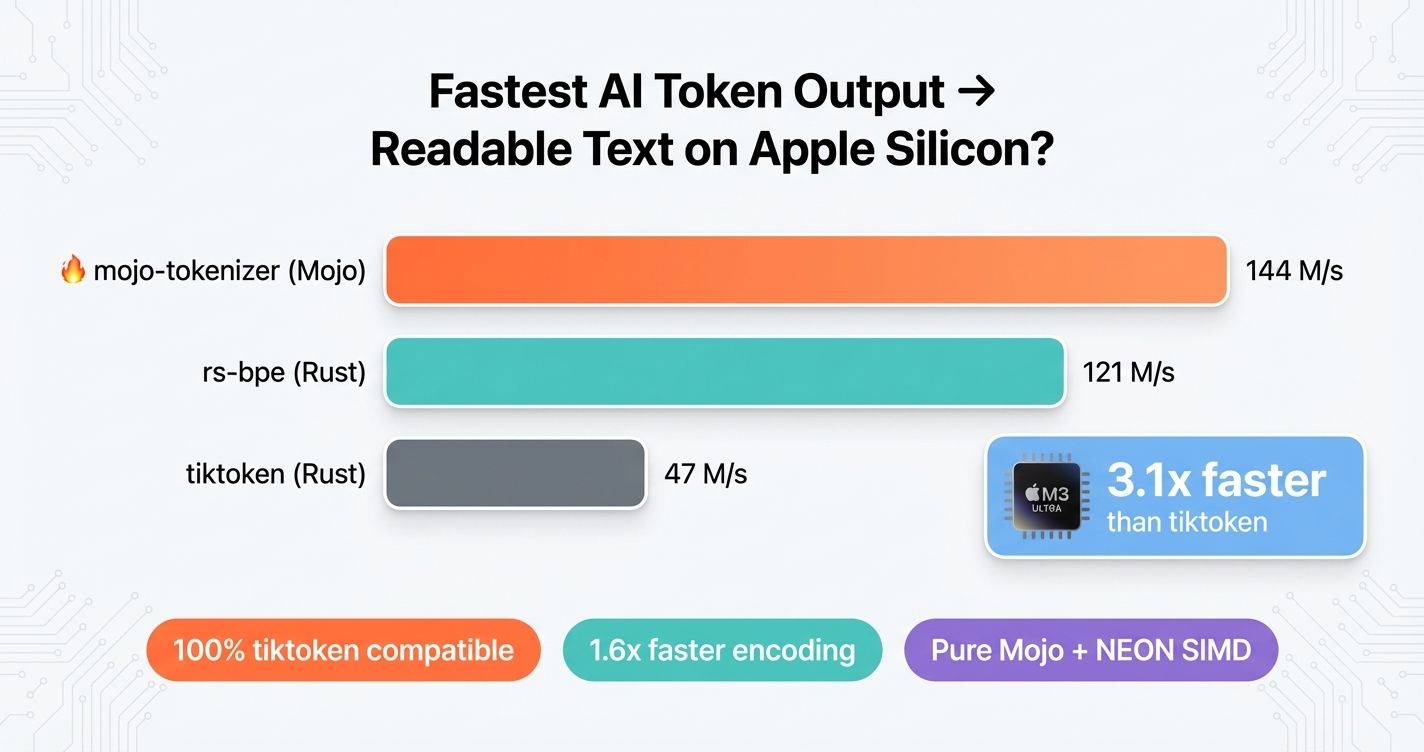
mojo-tokenizer decodes tokens at 144M tokens/sec on Apple Silicon — 3.1x faster than tiktoken and 1.2x faster than rs-bpe.
We benchmarked 3 BPE implementations across 5 diverse text files (23 MB total) using the GPT-4 tokenizer vocabulary. Every claim is backed by reproducible benchmarks with statistical analysis.
The Numbers
| Implementation | Language | Decoding | Encoding (full pipeline) |
|---|---|---|---|
| mojo-tokenizer | Mojo | 144 M/s | 8.0 M/s |
| rs-bpe | Rust | 121 M/s | — (raw BPE only) |
| tiktoken | Rust/Python | 47 M/s | 5.1 M/s |
20 iterations, 3 warmup. sherlock.txt (607 KB, 143K tokens). Apple Silicon.
Note: tiktoken is implemented in Rust with Python bindings — we're comparing against Rust-accelerated code, not pure Python.
Why decoding matters: Every LLM inference call decodes output tokens. At 144M tok/s, mojo-tokenizer can decode GPT-4's entire 128K context window in under 1ms.
Decoding Performance Across Files
| File | Type | mojo-tokenizer | rs-bpe | tiktoken | vs tiktoken |
|---|---|---|---|---|---|
| sherlock.txt | Literary | 144 M/s | 121 M/s | 47 M/s | 3.1x |
| war_and_peace.txt | Literary | 141 M/s | 114 M/s | 43 M/s | 3.3x |
| les_miserables.txt | Literary | 140 M/s | 122 M/s | 43 M/s | 3.3x |
| arxiv_abstracts.txt | Scientific | 117 M/s | 105 M/s | 42 M/s | 2.8x |
| wikitext2_train.txt | Encyclopedia | 128 M/s | 116 M/s | 45 M/s | 2.8x |
Speedup is consistent: 2.8x to 3.3x across all content types.
Encoding Performance (Fair Comparison)
| Implementation | Full Pipeline | Raw BPE |
|---|---|---|
| mojo-tokenizer | 8.0 M/s | 9.2 M/s |
| rs-bpe (Rust) | — | 10.0 M/s |
| tiktoken (Rust/Py) | 5.1 M/s | — |
Note: rs-bpe's raw BPE is faster (10.0 M/s). But production tokenizers need pretokenization to match tiktoken output. For the full pipeline, mojo-tokenizer beats tiktoken by 1.6x.
What We Test
| Metric | Description |
|---|---|
| Vocabulary | cl100k_base (100,256 tokens) — GPT-4, ChatGPT |
| Test data | 5 files: 607KB to 10.7MB (23MB total, 5.3M tokens) |
| Algorithm | O(n) backtracking BPE |
| Validation | 100% exact token match with tiktoken on all files |
Supported Formats
mojo-tokenizer currently focuses on OpenAI-style BPE tokenization:
| Encoding | Vocab Size | Models | Status |
|---|---|---|---|
| o200k_base | 199,998 | gpt-5.2, gpt-oss-120B, gpt-oss-20B | ✓ Verified |
| HuggingFace BPE | varies | Qwen, Llama, Mistral | Experimental |
"Hello, world!" → [13225, 11, 2375, 0] (o200k_base)mojo-tokenizer produces exact token matches with tiktoken on o200k_base. HuggingFace BPE format loading is implemented but not yet validated against HuggingFace tokenizers.
How It Works
FlatTokenStorage: The Decoding Secret
The key to 144M tok/s decoding is FlatTokenStorage — a flat byte array containing all token bytes contiguously:
Traditional storage:
token_0 → [72, 101, 108, 108, 111] # "Hello" - separate allocation
token_1 → [32, 119, 111, 114, 108, 100] # " world" - separate allocation
...100K more allocations...
FlatTokenStorage:
data: [72, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100, ...]
offsets: [0, 5, 11, ...] # Where each token startsDecoding becomes a series of memcpy() calls instead of 100K pointer dereferences:
# For each token ID, copy its bytes directly
memcpy(dest_ptr, flat_data + offsets[token_id], lengths[token_id])Source: src/flat_token_storage.mojo
O(n) Backtracking BPE (Encoding)
Ported from rs-bpe. Single forward pass with merge table instead of priority queue:
Traditional BPE: O(n log n) - priority queue for merges
Backtracking BPE: O(n) - single pass with precomputed tablesPairCache1000: O(1) Merge Lookup
For token pairs where both < 1000 (covers ~80% of merges):
# HashMap: merge_rank = self.merges.get(pair_key) # O(1) amortized
# Array: merge_rank = self.pair_cache[t1][t2] # O(1) guaranteed4MB 2D array eliminates hash overhead. +21% encoding speedup.
Zero-Copy Borrowed References
BacktrackEncoderRef borrows vocabulary instead of copying:
struct BacktrackEncoderRef[origin: Origin]:
var vocab: UnsafePointer[Vocabulary, origin] # BorrowedEliminates ~105MB copy per encode call. Compiler-enforced lifetime safety.
Statistical Rigor
All measurements include:
- 20 iterations per file (3 warmup)
- Standard deviation (CV < 5% indicates stable results)
- Percentiles (p50, p95, p99)
- 5 diverse text types (literary, scientific, encyclopedic)
sherlock.txt decoding:
Mean: 143.7 +/- 4.3 M/s
p50=144.4, p95=148.0, p99=148.3 M/s
CV=3.0%When Tokenization Matters
Cloud APIs (OpenAI, Claude, etc.) handle tokenization internally — you send text, they tokenize behind the scenes. But fast tokenization matters when:
- Running models locally — MLX, PyTorch, or llama.cpp require you to tokenize before inference
- Context window management — Counting tokens to fit within limits (128K for GPT-4, 200K for Claude)
- Cost estimation — Counting tokens before API calls to estimate costs
- Token-level operations — Prompt caching, continuation from specific positions
Example: Local Inference Pipeline
Text → [Tokenizer] → Token IDs → [LLM] → Output IDs → [Tokenizer] → Text
144M tok/s decode ↑ ↑ 8M tok/s encodeAt 144M tok/s, tokenizer overhead becomes negligible compared to model inference time.
Limitations
- Apple Silicon only — Results may differ on x86
- English-heavy data — CJK, Arabic, emoji not tested
- Vocabulary load time — mojo-tokenizer: ~800ms vs tiktoken: ~65ms
- Memory usage — mojo-tokenizer: ~10MB vs tiktoken: ~3MB
Try It
git clone https://github.com/atsentia/mojo-tokenizer
cd mojo-tokenizer
# Run comprehensive benchmark
mojo run bench_comprehensive.mojoFull methodology: docs/COMPREHENSIVE_BENCHMARK_RESULTS.md
These results are from Apple Silicon. We'd welcome community benchmarks on different platforms.
Appendix: Why Lead With Decoding?
Decoding is simpler than encoding — just look up bytes by token ID. But it's the operation that happens on every LLM output token, making it latency-critical.
At 144M tok/s:
- GPT-4's 128K context decodes in 0.9ms
- A typical 500-token response decodes in 3.5us
This makes tokenizer decoding effectively free compared to model inference time.
Appendix: Raw BPE vs Full Pipeline
You might notice rs-bpe's raw BPE (10.0 M/s) beats mojo-tokenizer (9.2 M/s). We don't lead with this because:
- Raw BPE produces different tokens — without pretokenization, you get valid BPE but not tiktoken-compatible output
- Production needs pretokenization — the regex patterns that split text before BPE
- Full pipeline is what you'd deploy — mojo-tokenizer's 8.0 M/s vs tiktoken's 5.1 M/s is the real comparison
We're honest about where Rust wins. Our advantage is in decoding and the full encoding pipeline.
Appendix: HuggingFace Trending Models (Jan 9, 2026)
Most trending models on HuggingFace use BPE tokenization:
| Model | Tokenizer | Vocab Size |
|---|---|---|
| LiquidAI/LFM2.5-1.2B-Instruct | BPE | 64,400 |
| MiniMaxAI/MiniMax-M2.1 | GPT2/BPE | 200,000 |
| naver-hyperclovax/HyperCLOVAX-SEED-Think-32B | GPT2/BPE | 128,000 |
| LGAI-EXAONE/K-EXAONE-236B-A23B | BPE | 153,600 |
| IQuestLab/IQuest-Coder-V1-40B | BPE | 75,858 |
| tencent/HY-MT1.5-1.8B | BPE | 120,000 |
| Qwen/Qwen2-1.5B | BPE | 151,643 |
| mistralai/Mistral-7B-v0.1 | BPE | 32,000 |
| nvidia/nemotron-speech (ASR) | SentencePiece | — |
| Lightricks/LTX-Video | Visual encoder | — |
Status: These models use BPE format. HuggingFace BPE loading in mojo-tokenizer is not yet validated — the loader parses tokenizer.json but doesn't produce matching tokens yet. Use tiktoken/o200k_base for production (verified to match exactly).
Multimodal models (Qwen-VL, LTX-Video) use BPE only for text. Images/videos use vision encoders.
mojo-tokenizer is early-stage software. While benchmarks are rigorous, the API may change. We welcome contributions and bug reports at github.com/atsentia/mojo-tokenizer.
Originally posted at atsentia.com blog